Auf Knopfdruck: PDFs in Anwendungen erstellen mit HTML und CSS-Modul
Bernhard Jungwirth
(Bild: Black Jack/Shutterstock.com)
In E-Government- und Geschäftsanwendungen, aber auch im Schriftverkehr gilt es, Daten automatisiert als PDF verfügbar zu machen. Wie gelingt das am besten?
Daten automatisiert als PDF verfügbar zu machen oder PDF-Dokumente für den Schriftverkehr zu erstellen, ist eine gängige Anforderung, mit der sich die Entwickler von E-Government- und Geschäftsanwendungen konfrontiert sehen. Die Daten aus verschiedenen Datenquellen und Formaten sollen auf Knopfdruck in ein Layout, entsprechend den Designvorgaben des Unternehmens oder Auftraggebers, umgewandelt werden, und zwar integriert in ihre jeweils eingesetzte Anwendung beziehungsweise Systemumgebung.
Ein Anwendungsfeld für automatisch generierte PDF-Dokumente sind Rechnungen, Rücksendeformulare und Bestellbestätigungen im Online-Shopping. Diese Dokumente sind meistens relativ einfach aufgebaut, es gibt eine Anschrift, allgemeine Rechnungsdaten und anschließend eine tabellarische Auflistung der Produkte. Im Banken- und Versicherungswesen sind PDFs ebenfalls gefragt, denn der Kontoauszug kommt nicht mehr aus dem Automaten, sondern wird über das Online-Banking heruntergeladen. Dokumente, die im Zusammenhang mit der Coronakrise erforderlich geworden sind – wie Testzertifikate, Quarantänebescheide und Impfzertifikate mit QR-Code – lassen sich ebenfalls vielfach als PDF automatisiert erstellen und ausfertigen.
Young Professionals schreiben für Young Professionals
Dieser Beitrag ist Teil einer Artikelserie, zu der die Heise-Redaktion junge Entwickler:innen einlädt – um über aktuelle Trends, Entwicklungen und persönliche Erfahrungen zu informieren.
Bist du selbst ein "Young Professional" und willst einen (ersten) Artikel schreiben? Schicke deinen Vorschlag gern an die Redaktion: developer@heise.de. Wir stehen dir beim Schreiben zur Seite.
Durch die angepassten Regeln mussten Interessierte für Veranstaltungen im Vorhinein Reservierungen oder Tickets buchen, und auch diese werden zumeist als PDF verschickt. Die geltenden Gesetze und Verordnungen stehen in vielen Ländern ebenso als PDFs zur Verfügung. Bei der Zusammenstellung einzelner Gesetze zu einer Sammlung oder allgemein bei Druckprodukten für einen Verlag werden die Anforderungen an die Typografie höher als bei einer Rechnung. Bücher sind meistens im Blocksatz gedruckt, dies erfordert eine funktionierende Silbentrennung und auch Seitenumbrüche wollen genau gesteuert werden.
Diese Aufstellung zeigt, dass PDF als Format für viele Anwendungsfälle etabliert ist. Zum Erstellen der Dokumente gibt es eine umfangreiche Liste an Werkzeugen für verschiedene Programmiersprachen und Systemumgebungen.
Die Information, mit welchem Programm ein PDF erstellt wurde, ist in den Dokumenteigenschaften zu finden. Im Beispiel der IKEA-Rechnung (s. Abb. 1) ist als Anwendung JasperReports eingetragen [8] und die Datei selbst ist mit iText 2.1.7 erstellt. JasperReports ist ein Werkzeug für Java zum Erzeugen von Berichten und steht als Open Source zur Verfügung. Zur Gestaltung der Berichte gibt es mit Jaspersoft Studio einen WYSIWYG-Editor (What you see is what you get).
Die Programmbibliothek iText kommt im Zusammenhang mit dem automatisierten Erstellen von PDF-Dateien häufig vor. Die Bibliothek ist Open Source und wurde lange Zeit unter der LGPL-Lizenz angeboten (GNU Lesser General Public License), daher ist iText in vielen weiteren Anwendungen zur PDF-Erstellung enthalten.
PDF-Dokumenteigenschaften einer IKEA Rechnung (Abb. 1)
Mit der Ende 2009 erschienen Version 5.0 von iText [9] hat sich die Lizenz auf AGPL (GNU Affero General Public License) geändert. Die neue Lizenzierung soll ein potenzielles Schlupfloch der allgemeinen GNU General Public License schließen: Das Verwenden einer neuen iText-Version ist nur gestattet, wenn Entwickler den eigenen Quellcode offenlegen. Das ist jedoch nicht in jedem Fall möglich und führt dazu, dass bei vielen Projekten, die nicht Open Source sind oder die keine kostenpflichtige Version verwenden, heutzutage eine veraltete iText-Bibliothek in Verwendung ist. Hiervon sind nicht nur kleine Anbieter betroffen. Unter anderem Amazon beschreitet den knausrigen Weg veralteter Software: In den Dokumenteigenschaften der PDFs aktueller Amazon-Geschenkgutscheine ist zu lesen, dass die Gutscheine mit iText 2.0.8 erstellt werden – einer Version der Bibliothek aus dem Jahr 2008.
Neben iText ist in vielen Dokumenten auch Apache FOP (Formatting Objects Processor) eingetragen. Dabei handelt es sich um die XML-Anwendung XSL-FO (Formatting Objects), und mit Apache FOP vom XML Graphics Project gibt es eine Open-Source-Software zum Erstellen von Dokumenten [10]. Diese Formatierungssprache eignet sich zur seitenformatierten Anordnung von Elementen für den Druck als Ausgabeformat und wurde im W3C entwickelt [11], aber die Weiterentwicklung am Standard ist seit 2013 eingestellt. Als Nachfolger gilt die CSS Paged Media Technologie, auf welche nachfolgend detailliert eingegangen wird. Durch die Verbreitung von XML als Austauschformat bei Geschäftsanwendungen ließen sich damit die Daten über XSLT (Extensible Stylesheet Language Transformation) in Druckdaten umwandeln. Eine Übersicht zu der Sprache und ihrer Anwendung ist auf der Website Data2Type zu finden [12].
Neben den genannten Werkzeugen lassen sich aber auch HTML und CSS zum Erstellen von PDFs einsetzen. Diese Technologien dominieren als Formatierungssprache das Web und können medienübergreifend auch für gedruckte und paginierte Layouts verwendet werden.
HTML und CSS: Die Grundlagen aus dem Web
Cascading Style Sheets (CSS) ist eine Sprache zum Aufbereiten der Darstellung von HTML-Dokumenten, um eine Trennung von Inhalt und Layout zu erreichen. Die Formatierung war ursprünglich auf die Ausgabe auf Bildschirmen ausgelegt. Mit der Einführung des CSS Paged Media Moduls ist CSS für die Darstellung von Inhalten für seitennummerierte Medien erweitert [14]. Diese Erweiterung ist ein W3C-Standard und wird laufend weiterentwickelt. Wichtige Eigenschaften, die das Modul steuert, sind die Größe und Orientierung einer Seite sowie Kopf- und Fußzeilen und die Seitennummerierung.
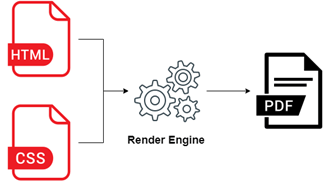
Damit aus einer HTML- oder XML-Datei und der zugehörigen CSS-Datei eine Webseite wird, übernimmt der Browser das Rendering. Zum Erstellen von PDF-Dateien werden eigene Render Engines benötigt. Es stehen verschiedene Implementierungen bereit, sowohl kommerziell als auch Open Source und in verschiedenen Programmiersprachen.
Schematische Darstellung der Render Engine (Abb. 2)
Abbildung 2 zeigt den Ablauf: Eine HTML-Datei wird zusammen mit der CSS-Datei an die Render Engine übergeben, die daraus ein PDF-Dokument erstellt.
Beispiele für kostenpflichtige Programme sind Prince [17] und Antenna House CSS Formatter [18]. Als Open-Source-Implementierung gibt es unter anderem Weasyprint [19] und PagedJS [20]. Für einfache Layouts wie eine Rechnung kommen die Open-Source-Optionen infrage, aber bei komplexeren Layouts mit laufender Kopfzeile oder Fußnoten bieten nur die kostenpflichtigen Programme den erforderlichen Funktionsumfang an.
Da die Layoutanweisungen durch das CSS Paged Media Module standardisiert sind, ist es möglich, die eingesetzten Renderer zu wechseln – wie bei einem Wechsel zwischen Browsern. Allerdings gibt es auch einige herstellerspezifische Erweiterungen, die ihre Nutzer mit der Zeit an einen bestimmten Hersteller binden.
Die Regel @page definiert eine Seite und legt damit die Eigenschaften des Dokuments für den Druck fest. Sie kann allgemein gelten oder über einen Bezeichner beziehungsweise Pseudoklassen nur für bestimmte Seiten zur Anwendung kommen. Über die Eigenschaft size lassen sich das Format und die Ausrichtung der Seite steuern, vordefinierte Formate wie DIN-A4 verwenden oder ein individuelles Format mit Breite und Höhe, beispielsweise für Gutscheine, festlegen. Eine Seite basiert wie HTML-Inhalte für das Web ebenfalls auf dem Boxmodell und margin kann den Rand festlegen, ebenso lassen sich der Innenabstand (padding) und ein Rahmen (border) setzen. Wie bereits erwähnt gibt es auch Pseudoklassen, und mit :left und :right ist ein unterschiedliches Layout für die rechte und linke Seite definierbar (Listing 1).
Die vollständige Spezifikation ist beim World Wide Web Consortium nachzulesen.
Die Steuerung von Druckmarken im professionellen Druck erfolgt mit der Eigenschaft marks. Der Wert crop aktiviert den Abdruck von Schnittmarken und mit dem Wert cross lassen sich auch Crossmarks zur Ausrichtung im Druckverfahren hinzufügen.
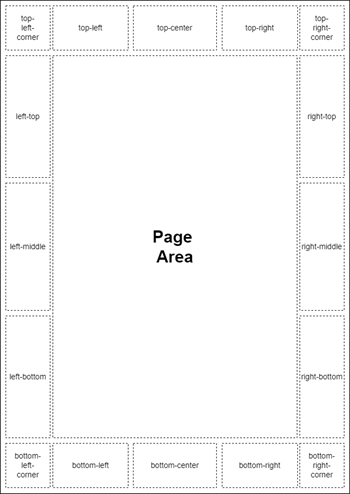
Das Seitenmodell und die Bezeichner der Page Margin Boxes
Die Unterteilung eines HTML-Dokuments mit CSS Paged Media zur Ausgabe auf Seiten geschieht in einer "page box" – für jede Seite existiert eine eigene. Diese Seite hat von außen nach innen einen Rand (page margin), einen Rahmen (page border), einen Abstand (page padding) und den Inhalt (page area). Der Rand hat eine besondere Funktion, denn er ist für generierte Inhalte einer Seite wie die Seitennummer in der Fußzeile oder einen Titel in der Kopfzeile zuständig. Dafür gibt es eine Unterteilung in 16 Boxen, wobei wiederum jede Box einen eigenen Rand, Rahmen und Abstand sowie Inhalt besitzt. Abbildung 3 zeigt das Seitenmodell und die Bezeichner der Page Margin Boxes.
Seitenmodell mit Margin Boxes (Abb. 3)
Die Boxen lassen sich innerhalb der @page-Regel ebenfalls über eine @-Regel ansteuern. Listing 2 zeigt die CSS-Regeln einer Seite zur Anzeige einer mittigen Fußzeile mit der Seiteninformation "Seite 1 von 3". Die Seitenzahl und -anzahl ermittelt die counter-Funktion. Dieser Counter für die Seitennummerierung ist automatisch vorhanden, und zusätzlich lassen sich auch eigene Counter-Funktionen erstellen.
Listing 2: Generierter Inhalt für die Page Margin Box (Fußzeile)
Nachdem das Layout der Seite definiert ist, geht es weiter zur Aufbereitung des Inhalts.
Den Seitenumbruch schützen gegen typografische Schönheitsfehler
Im Gegensatz zu Inhalten im Browser, die kontinuierlich scrollbar sein können, benötigen die seitenbasierten Layouts Steueranweisungen für Umbrüche. Damit die oberste Überschriftenebene eines Kapitels immer auf einer neuen Seite beginnt, ist mit der Regel page-break-before: always ein Seitenumbruch zu forcieren. Zusätzlich sollen Zwischenüberschriften nicht am Ende einer Seite stehen, wofür sich mit page-break-after: avoid der Seitenumbruch direkt danach unterbinden lässt (Listing 3).
Innerhalb eines Textabsatzes können durch den Seitenumbruch ebenfalls unschöne Satzfehler entstehen, die in der Typografie als Witwen und Waisenkinder bezeichnet werden.
Befindet sich die letzte Zeile eines Absatzes auf einer neuen Seite, sprechen Layouter von einer Witwe (widow) – dafür ist weiterhin auch noch der ältere Fachbegriff "Hurenkind" gängig. Steht die erste Zeile eines Absatzes auf einer Seite und der Rest auf einer neuen Seite, heißt dieser typografische Schönheitsfehler im Druckereijargon "Schusterjunge" beziehungsweise Waise (orphan).
Diese Fehler beeinträchtigen den Lesefluss und sehen im Layout nicht ästhetisch aus, daher sind sie zu vermeiden. In Listing 3 ist die Einstellung so gewählt, dass mindestens drei Zeilen eines Absatzes am Beginn oder am Ende einer Seite stehen müssen.
Inhaltsverzeichnis und Indexerstellung
Zur Orientierung in einem mehrseitigen Druckwerk ist ein Inhaltsverzeichnis hilfreich.
Mit den Funktionen aus dem CSS Generated Content for Paged Media Module [22] lässt sich das Inhaltsverzeichnis erstellen. Der HTML-Code dafür besteht aus einfachen Listen mit Links, wie es auch im Web für die Navigation üblich ist. Damit die Links im PDF-Dokument auf die richtige Seite verweisen, gilt es, die Funktion target-counter(attr(href), page) aufzurufen und als Parameter das Attribut href des Links sowie den Counter page zu verwenden (Listing 4).
Für die automatisierte Erstellung mit einer Anwendung als Webservice lassen sich noch weitere Techniken kombinieren, so ist eine Kombination aus Java-Code und Template-Engines machbar. Zur Verwendung unternehmensweiter Designs für die Kopf- und Fußzeile können diese in HTML Templates ausgelagert und mittels Template-Engines verarbeitet werden. Template-Engines sind Programme, die Vorlage-Dateien verarbeiten und definierte Platzhalter mit Daten befüllen – für diese Aufgabe sind Bibliotheken in verschiedenen Programmiersprachen verfügbar. Im Umfeld von Java und Spring Boot bietet sich die Java-basierte Engine Thymeleaf an [23].
Durch die reibungslose Integration von Spring Boot und Thymeleaf ist die Konfiguration (Listing 5) der Template-Engine schnell erledigt.
@Bean
public ClassLoaderTemplateResolver templateResolver() {
ClassLoaderTemplateResolver templateResolver = new ClassLoaderTemplateResolver();
templateResolver.setPrefix("templates/");
templateResolver.setTemplateMode(TemplateMode.HTML);
templateResolver.setSuffix(".template.html");
templateResolver.setCharacterEncoding("UTF-8");
return templateResolver;
}
@Bean
public SpringTemplateEngine templateEngine() {
SpringTemplateEngine engine = new SpringTemplateEngine();
engine.setTemplateResolver(templateResolver());
return engine;
}
Listing 5: Konfiguration Template-Engine in TemplateConfiguration.java
Die Vorlagen für den Report sind aufgeteilt in eine Gesamtdatei (report.template.html) und in eine Kapitelvorlage (chapter.template.html). Das Report-Template (Listing 6) erzeugt eine Coverseite mit dem div-Container mit der ID "cover" und eine Seite für das Inhaltsverzeichnis mit der ID "toc". Danach beginnt der Inhalt des Reports und für jedes Kapitel bindet das Programm das Kapitel-Template ein. Im HEAD-Bereich lassen sich die Metadaten für das PDF-Dokument angeben.
Listing 7: Kapitel-Template (Ausschnitt aus dem HTML-Body)
Zum Befüllen der Templates werden die Daten in einfache Java Objekte abgebildet, so gibt es zum Chapter-Template eine Chapter-Klasse in Java mit der Liste der E-Ladestellen zum Befüllen der Tabelle (Listing 8).
public class Chapter {
private String title;
private Long bezirk;
private List<ELadestelle> ladestellen;
// getter and setter
}
Listing 8: Chapter.java
Das Einlesen und Aufbereiten der Daten von der Datenquelle erfolgt im Beispielcode mit der Implementierung im OpenDataService. Für das Erstellen des Berichts werden die Daten als Map im Key-Value-Format aufbereitet (Listing 9).
public Map<String,Object> generateValuesForReport() {
Map<String,Object> values = new HashMap<>();
List<Chapter> chapters = new ArrayList<>();
List<IndexEntry> indexEntries = new ArrayList<>();
values.put("title", "E-Ladestellen in Wien");
values.put("chapters", chapters);
values.put("index", indexEntries);
List<ELadestelle> loadingPoints;
try {
loadingPoints = getELadeStelleData();
Map<Long, List<ELadestelle>> loadingPointsForDistrict = groupLoadingPointByDistrict(loadingPoints);
for(var entry : loadingPointsForDistrict.entrySet()) {
Chapter c = new Chapter();
IndexEntry index = new IndexEntry();
String title = "Ladestellen im "+entry.getKey()+". Bezirk";
c.setBezirk(entry.getKey());
c.setTitle(title);
c.setLadestellen(entry.getValue());
chapters.add(c);
index.setTitle(title);
index.setTarget(entry.getKey().toString());
indexEntries.add(index);
}
} catch (IOException e) {
e.printStackTrace();
}
return values;
}
Listing 9: Die Kapitel und das Inhaltsverzeichnis aufbereiten
Jedes Kapitel erhält dabei einen Eintrag in der Liste "chapters" und zusätzlich entsteht eine Liste "index", die die Einträge für das Inhaltsverzeichnis aufnimmt. Damit das Inhaltsverzeichnis im PDF-Dokument und als HTML-Code funktioniert, kommt als ID-Element die Nummer des Bezirks zum Tragen (entry.getKey()), die auch in der gruppierten Liste an E-Ladestellen als Key Verwendung findet. Somit ist die Referenz beim HTML-Attribut href richtig gesetzt und die PDF Render Engine kann die Seitennummer dank dieser eindeutigen Konkordanz richtig zuordnen.
Die Implementierung im PDFGenerationService erstellt zunächst aus den Templates die HTML-Datei und damit anschließend das PDF-Dokument. Diese einfache Reporting-Anwendung liefert als Ergebnis eine HTML-Datei ohne Styling und ein PDF-Dokument. Soll die HTML-Datei auch als Webansicht verwendet werden, kann zusätzlich noch ein eigenes CSS für den Browser erstellt werden. Somit erstellt die Anwendung ein semantisch korrektes HTML-Dokument aus den Ausgangsdaten, welches durch die saubere Trennung der Darstellungsvorgaben in verschiedene Formate überführt werden kann.
Im Beispiel mit den E-Ladestellen würde sich auch eine Darstellung als Kartenansicht anstatt einer Tabelle anbieten. Die Render Engines unterstützen grundsätzlich die Ausführung von eingebundenem JavaScript, aber inwiefern Kartenansichten oder auch Diagramme mit externen Bibliotheken funktionieren, kann beim jeweiligen Hersteller nachgesehen werden. Die Einbindung einer Karte oder eines Diagramms als SVG (Scalable Vector Graphics) sollte immer funktionieren.
PrintCSS bietet vielfältige Einsatzmöglichkeiten
Die im Artikel besprochenen Techniken lassen sich an die individuellen Anforderungen und bereits vorhandenen Werkzeuge sowie Verarbeitungsprozesse an seine Projekte anpassen und konfigurieren. Dadurch, dass viele Geschäftsanwendungen als Web-Anwendung entwickelt werden, können Entwickler auf bestehendes Wissen zu HTML und CSS zurückgreifen und müssen keine eigene Formatierungssprache für die PDF-Ausgabe lernen.
PrintCSS ist eine ausgesprochen spannende Technik mit vielfältigen Einsatzmöglichkeiten, angefangen vom Erstellen von Eintrittskarten für den Versand als PDF bis hin zur Automatisierung der Druckdatenerstellung bei Verlagen. In vielen Bereichen ist es ein Nachteil, dass es keinen intuitiv bedienbaren WYSIWYG-Editor gibt, aber für eine Vorschau des Inhalts kann auch ein Browser verwendet werden. Die seitenbezogenen Steuerungen wie Kopf- und Fußzeile, sowie Inhaltsverzeichnis erfordern ein Rendering als PDF zur Kontrolle des Layouts.
Young Professionals schreiben für Young Professionals